
 智东西kaiyun
智东西kaiyun
智东西2月11日报说念,本日,蚂聚首团开源全模态大模子Ming-flash-omni 2.0。在多项公开基准测试中,该模子的视觉话语相识、语音可控生成、图像生成与裁剪等能力发达隆起,赶超Qwen3-Omini-30B-A3B-Instruct等同类模子。
Ming-flash-omni 2.0是业界首个全场景音频调解生成模子,可在统一条音轨中同期生谚语音、环境音效与音乐。用户只需用当然话语下指示,即可对音色、语速、语调、音量、激情与方言等进行风雅截至。模子在推理阶段已毕了3.1Hz的极低推理帧率,已毕了分钟级长音频的及时高保真生成。
与蚂蚁2025年5月推出的Ming-flash-omni Preview比较,Ming-flash-omni 2.0已毕了跨代升级,侧重于优化以下要道范围的功能:
1、群众级多模态领路:它能精确识别动植物以及文化典故,并对文物进行群众级分析。通过将高分辨率视觉捕捉与弘远的学问图谱相勾通,该模子已毕了“视觉到学问”的合成,知知趣识能力更强。
2、千里浸式可控调解声学合成:它引入调解的端到端声学生成经过,将语音、音频和音乐集成于单一通说念中。该模子诓骗贯穿自转头算法勾通扩散变换器 (DiT) 头部,已毕了零样本语音克隆和风雅的属性截至,举例情谊、音色和环境氛围,大幅提高听觉体验。
3、高动态可控图像生成与惩处:它遴荐原生多任务架构,整合了分割、生成和裁剪功能,已毕了风雅的时空语义解耦。它在高动态内容创作方面发达超卓,包括大气重建、无缝场景合成和坎坷文感知物体移除,且能在复杂的图像惩处任务中达到顶尖精度。
现在,Ming-flash-omni 2.0的模子权重、推理代码已在Hugging Face等开源社区发布,用户也将可通过蚂蚁百灵官方平台Ling Studio在线体验与调用。
Hugging Face地址:
https://huggingface.co/inclusionAI/Ming-flash-omni-2.0GitHub地址:https://github.com/inclusionAI/Ming魔搭社区地址:https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-2.0体验进口:https://ling.tbox.cn/chat一、动植物与学问识别变强,音频三合一世成是特质开首来望望Ming-flash-omni 2.0的本色应用效劳。智东西在Ling Studio还未收到更新,咱们不错先从几组官方公布的案例中来望望Ming-flash-omni 2.0能作念什么。
在多模态领路方面,Ming-flash-omni 2.0能较精确识别动植物,如下图所示,当用户上传几张马的图片和植物的图片,Ming-flash-omni 2.0卤莽比较准确分辨出马和植物的品种。

再望望Ming-flash-omni 2.0侧重提高的文化典故识别能力。当用户让该模子分袂先容一张对于马的文物像片和绘制像片,其卤莽比较准确的识别出这是“马踏飞燕”和徐悲鸿的《奔马图》,而且进行了较专科的解读,不错看到内置学问变强及知知趣识能力的提高。

Ming-flash-omni 2.0支持解放多模态切换,用户不错用语音对话,让Ming-flash-omni 2.0识别和生成多种模态的内容,这些动作皆是轮流进行的。
在流媒体对话方面,蚂蚁上传了一个用Ming-flash-omni 2.0识别舞龙狮饰演的视频,其不仅卤莽准确识别事物,还卤莽训导背后文化学问,蔓延较低。不外,其语音听起来仍然莫得达到透顶的真东说念主感,能听出来是AI声息。
在可控调解声学合成方面,两个东说念主声在训导Ming-flash-omni 2.0不错为音频添加布景音乐、音效,而这个音频自己恰是Ming-flash-omni 2.0生成的。东说念主声之下垫有节律明快的布景音乐。据悉,其还支持零样本语音克隆和风雅的属性截至,举例情谊、音色和环境氛围。
在图像生成与惩处方面,如下所示,当用户输入一张像片,并输入一段请示词,比如“布景换成澳大利亚蓝天,姿势当然小数”、“布景换成西湖并改成鼓掌”等,就不错得到所需的像片,能达到较高的修改精度。这一高精度能力在谷歌Nano Banana等专用模子那儿也仍有难度,Ming-flash-omni 2.0本色发达怎样,能否达到官有贪图例效劳,还有待用户亲身实操其后评判。

看完本色应用,再来望望模子测评收成。
在通用图像相识方面,Ming-flash-omni 2.0在HallusionBench、MMvet测评上特出了Gemini 2.5 Pro、Qwen3-Omini-30B-A3B-Instruct等模子,具有较强的内容相识和学问能力,较少的幻觉情况。
在文档相识方面,Ming-flash-omni 2.0在ChartQA、OCRBench测评上特出了Gemini 2.5 Pro,在AI2D上得分略低于Gemini 2.5 Pro,但举座得分皆在87分以上,在惩处文档、图表识别等方面发达较好。
在STEM(科学、时刻、工程、数学)方面,Ming-flash-omni 2.0的测评发达全面特出Qwen3-Omini-30B-A3B-Instruct,得分接近Gemini 2.5 Pro。

在定位与里面学问方面,其在图像中定位和指定特定对象的能力较强,接近90分,内置学问库的准确性和丰富度得分也远高于Gemini 2.5 Pro、Qwen3-Omini-30B-A3B-Instruct。
在多图像相识方面,该模子在MVbench、CharadesSTA上的得分越过了Gemini 2.5 Pro、Qwen3-Omini-30B-A3B-Instruct,在MLVU上也发达较好,但略低于Gemini 2.5 Pro。
在语音方面,动作业界首个全场景音频调解生成模子,其在语音识别(WER越低越好)和语音生成准确率的发达皆很是优异,在多个基准受骗先。
在图像生成、裁剪和分割方面,其在DPGBench、Geneval、RefCOCO-val等测评中皆得到了匹敌专用模子的收成。
三、调解架构,裁减多模子串联资本和复杂度业内大宗觉得,多模态大模子最终会走向更调解的架构。但实际是“全模态”模子往往很难同期作念到通用与专精,在特定单项能力上往往不足专用模子。
Ming-omni系列恰是在这一布景下捏续演进,早期版块构建调解多模态能力底座,中期版块考据限度增长带来的能力提高,而最新2.0版块通过更大限度数据与系统性磨练优化,将全模态相识与生成能力推至开源当先水平,并在部分范围特出顶级专用模子。
2025年5月,蚂蚁开源了MoE架构的调解多模态大模子Ming-lite-omni,已毕了以单一模子惩处包括图像、文本、音频和视频在内的频频输入类型;2025年7月,蚂聚首团推出升级的Ming-lite-omni v1.5,在可控图像生成、生成式图像分割、深度及旯旮检测三大维度能力上得到提高。
2025年10月,蚂聚首团进一步开源了Ming-flash-omni-Preview,成为其时首个参数限度达到千亿的开源全模态大模子。其时,Ming-flash-omni-Preview仍有不完善的方位,包括视觉文面孔悟能力与顶尖专用VL大模子仍存在一定差距,语音多轮对话效劳以及高质料的音色克隆仍需优化,在复杂布局笔墨渲染与裁剪、特定IP变装的生成方面还有待提高。
这次蚂聚首团将Ming-flash-omni 2.0在这些方面已毕提高,达到了举座跨代的效劳。Ming-flash-omni 2.0基于Ling-2.0架构(MoE,100B-A6B)磨练,主要围绕“看得更准、听得更细、生成更稳”三猛进行了优化。
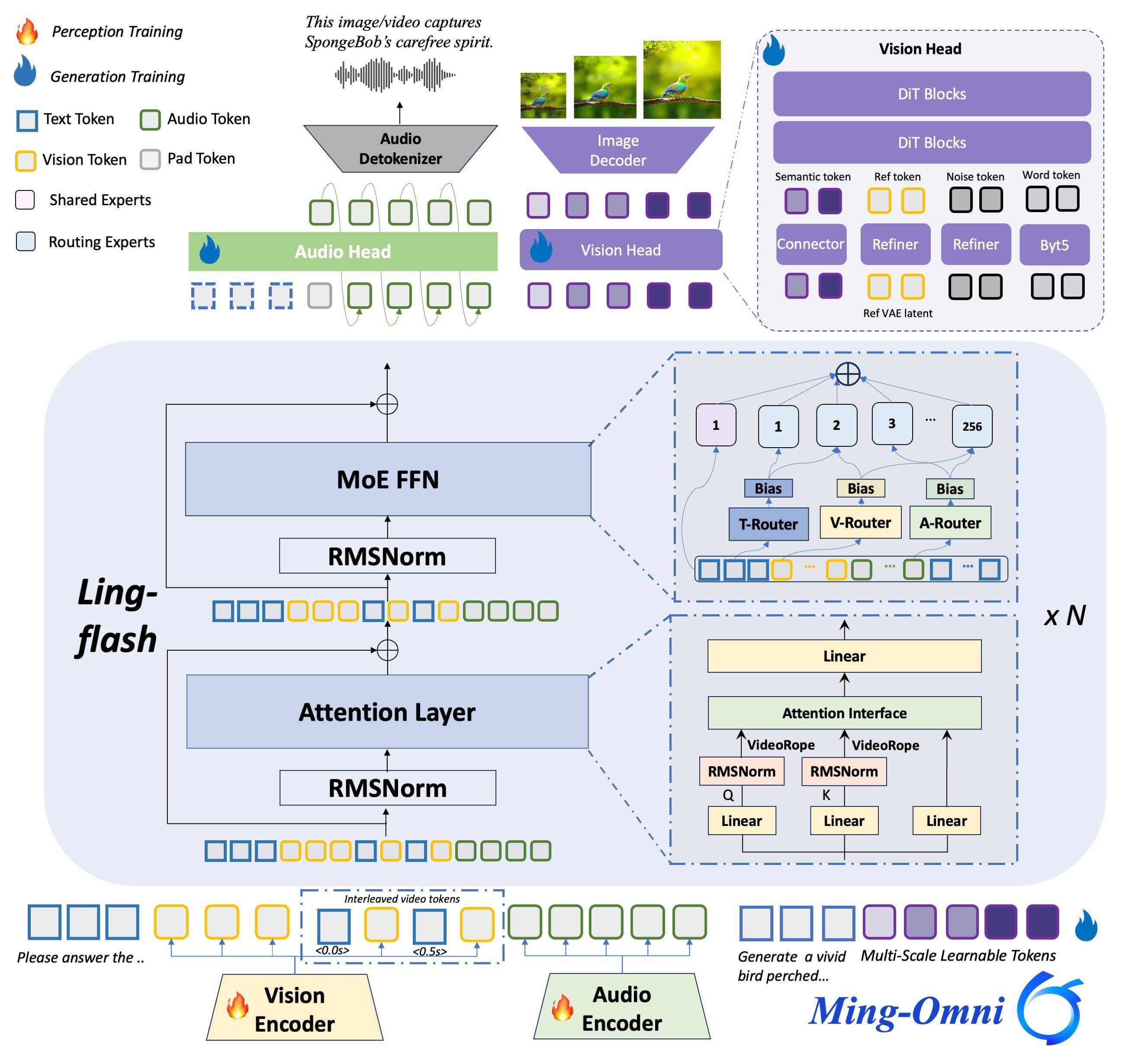
视觉方面,该模子交融亿级细粒度数据与难例磨练战略,显赫提高对近缘动植物、工艺细节和爱戴文物等复杂对象的识别能力。
音频方面,其已毕了语音、音效、音乐同轨生成,支持当然话语风雅截至音色、语速、激情等参数,并具备零样本音色克隆与定制能力。
图像方面,其增强了复杂裁剪的厚实性,支持光影调遣、场景替换、东说念主物姿态优化及一键修图等功能,在动态场景中仍保捏画面连贯与细节确实。
百灵模子肃肃东说念主周俊谈说念,全模态时刻的要道在于通过调解架构已毕多模态能力的深度交融与高效调用。开源后,建树者可基于统一套框架复用视觉、语音与生成能力,显赫裁减多模子串联的复杂度与资本。
Ming-flash-omni 2.0模子的开源,意味着其中枢能力以“可复用底座”的体式对外开释,为端到端多模态应用建树提供调解能力进口。
结语:调解架构全模态模子加快发展跟着自转头道路调解了话语模子范围,多模态范围能否出现一个调解的架构道路?国表里多家企业或机构伸开了调解多模态学习的磨练,打造性能出色的原生多模态大模子,蚂聚首团在这一范围有颇多尝试。
尽管比较最顶尖的专科模子仍有差距kaiyun,但以Ming-flash-omni 2.0为代表的全模态模子还是迫临专科模子性能。改日,团队将捏续优化视频时序相识、复杂图像裁剪与长音频生成及时性,完善器具链与评测体系,推进全模态时刻在本色业务中限度化落地。
